- 首页 主页 实时比分
- 赛事中心 球队数据 教练战术 历史对决 球迷互动
- 赛事聚焦 精彩瞬间 战术分析 数据统计 球员表现 赛场花絮 深度前瞻
- 赛程一览 各组赛程 关键对决 决赛路径
- 新闻资讯 赛场直击 球队动态 球员专访 赛事回顾 球迷故事 深度报道(世界杯赛程)
- 联系客服
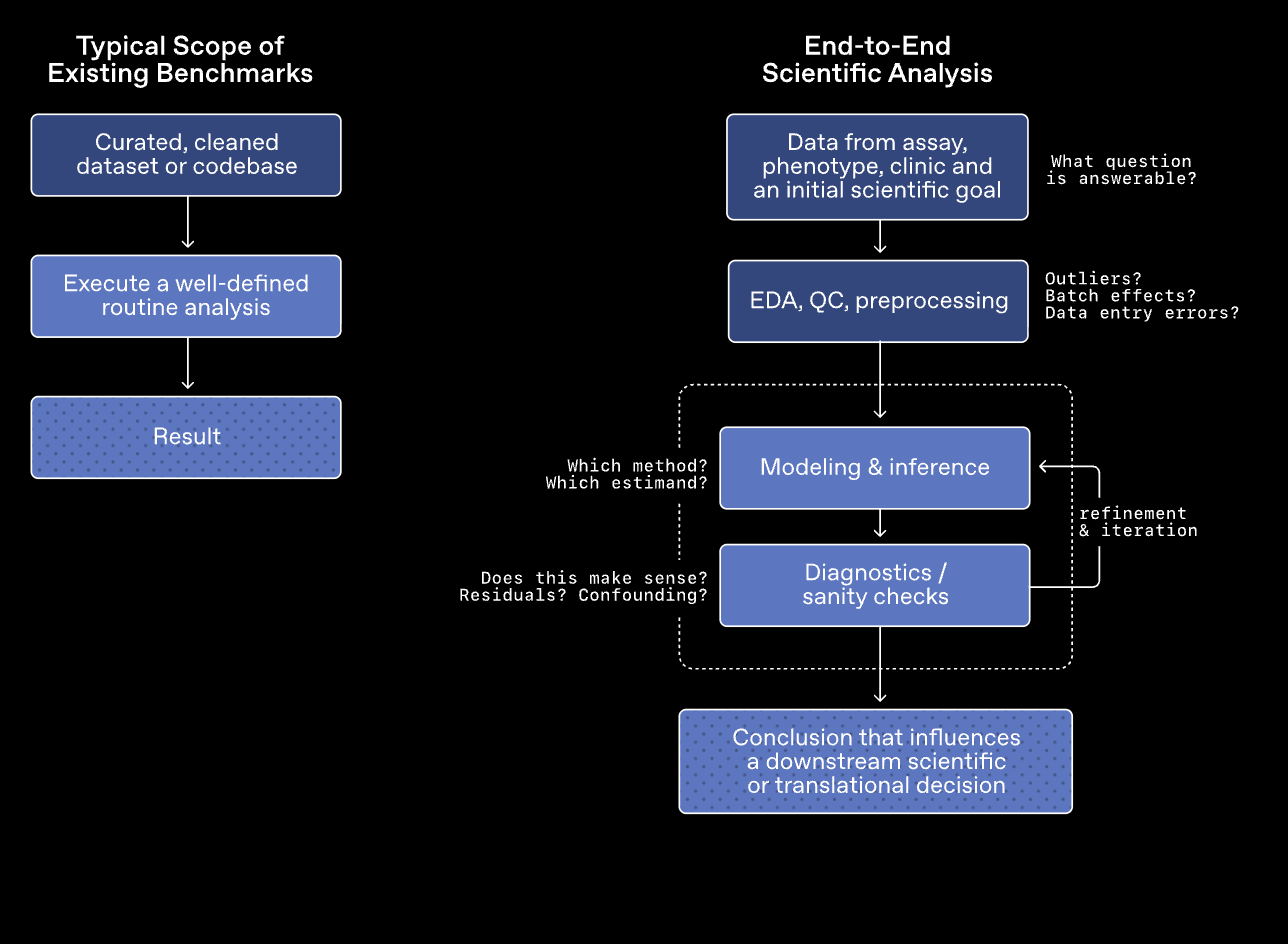
与以往侧重于考察模型是否能记住信息或遵循既定步骤的评估方法不同,GeneBench-Pro 旨在模拟真实科研情境,要求模型在面对数据不明确、信息缺失甚至含有噪声的情况下,进行判断和分析以得出结论。
GeneBench-Pro 涵盖了基因组学、定量生物学和转化医学等多个研究方向,总计包含 129 道测试题目。这些题目被划分为 10 个主要领域和 21 个子领域,涉及统计遗传学、群体遗传学、功能基因组学、蛋白质组学等多个分支。每道题目都为模型提供了一组接近实际科研环境的数据集,并附带简要的实验背景说明和一个与后续决策相关的目标。模型需要独立完成数据探索,选择合适的分析方法,并在过程中不断调整策略,最终给出答案。
为解决传统长流程基准测试中常见的评分偏差问题,OpenAI 在构建 GeneBench-Pro 时,核心采用了合成数据。这是因为如果直接使用历史真实数据出题,往往存在多种可行的分析路径,可能导致模型即使采用了错误的方法也可能偶然获得正确答案。
通过使用合成数据,OpenAI 可以完全掌握数据的底层因果关系和生成过程,从而更精确地评估模型是否真正理解了问题,而非仅仅通过“取巧”的方式得出结果。
目前,OpenAI 已在 Hugging Face 上公开了 10 道 GeneBench-Pro 的代表性示例题目,并提供了交互式界面供外部研究人员试用。后续,将有 50 道题目开放给 Artificial Analysis 进行第三方独立评估,以检验不同模型在这一基准测试上的实际表现。
| 主队 | 比分 | 客队 | 联赛 | 时间(北京) |
|---|---|---|---|---|
| 近期暂无比赛,请稍后再来查看。 | ||||